
Abstract
Almost all quantitative studies in educational assessment, evaluation and educational research are based on incomplete data sets, which have been a problem for years without a single solution. The use of big identifiable data poses new challenges in dealing with missing values. In the first part of this paper, we present the state-of-art of the topic in the Brazilian education scientific literature, and how researchers have dealt with missing data since the turn of the century. Next, we use open access software to analyze real-world data, the 2017 Prova Brasil , for several federation units to document how the naïve assumption of missing completely at random may substantially affect statistical conclusions, researcher interpretations, and subsequent implications for policy and practice. We conclude with straightforward suggestions for any education researcher on applying R routines to conduct the hypotheses test of missing completely at random and, if the null hypothesis is rejected, then how to implement the multiple imputation, which appears to be one of the most appropriate methods for handling missing data.
Prova Brasil; Missing data; R; Multiple imputation
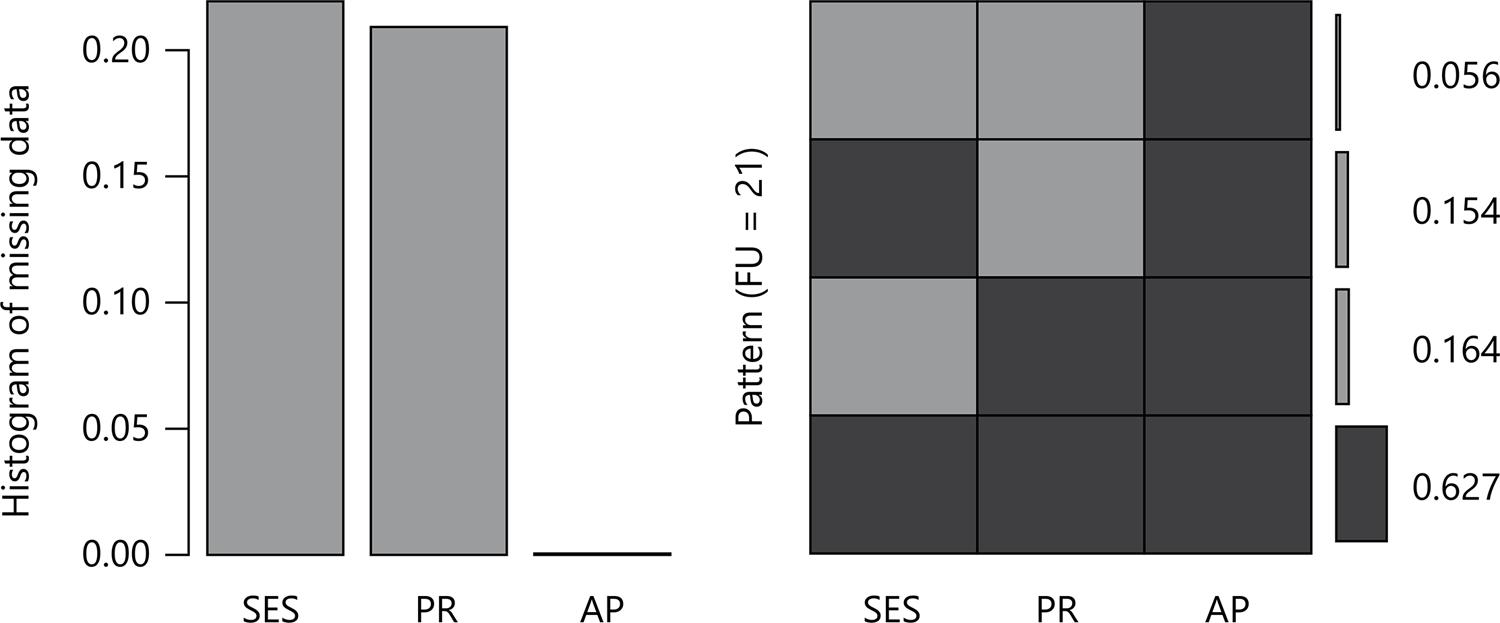 Source: own calculation (2019)
Source: own calculation (2019)
 Source: own calculation (2019)
Source: own calculation (2019)